Auto QA
Guide on how to perform automated QA on a Dataset.
Auto QA on BasciAIOur auto QA function can help you automatically detect labeling errors through scripts, such as missing labels or whether the object is within the specified effective area, etc. Auto QA improves the efficiency of quality inspection and automatically completes inspection tasks. The QA rules set in the data flow will be automatically updated and applied to the Task flow.
In this guide, we'll explore the specific details of different QA rules for the data, objects, or attributes, how to set up a Quality Check Job on the Dataset page, and also the instructions for our two main QA patterns: Real-time Auto QA on the Tool page and Bulk Auto QA on all the data in a Dataset. 🧙♂️
QA Rules
If you would like to enable the auto QA function, you'll need to select and configure the QA rules which you want to apply to the dataset. On the Dataset center, click a dataset and then navigate to the QA tab. On the Dataset-QA page, you will find the available QA rule list for the dataset. Select the rules which you want to apply to the dataset in the list, enable the rule buttons, and at last remember to click Save & Apply Changes to the Dataset. You can click Configure on the right side of each rule to configure it, or click View Instruction to view the rule details description. The rule configuration panel allows users to change the requirement type of a rule among Mandatory, Warning or Info (Violation of mandatory rules will prevent users from saving or submitting data).
Please remember to clickApply Changes to the Datasetafter you select and enable certain QA rules.
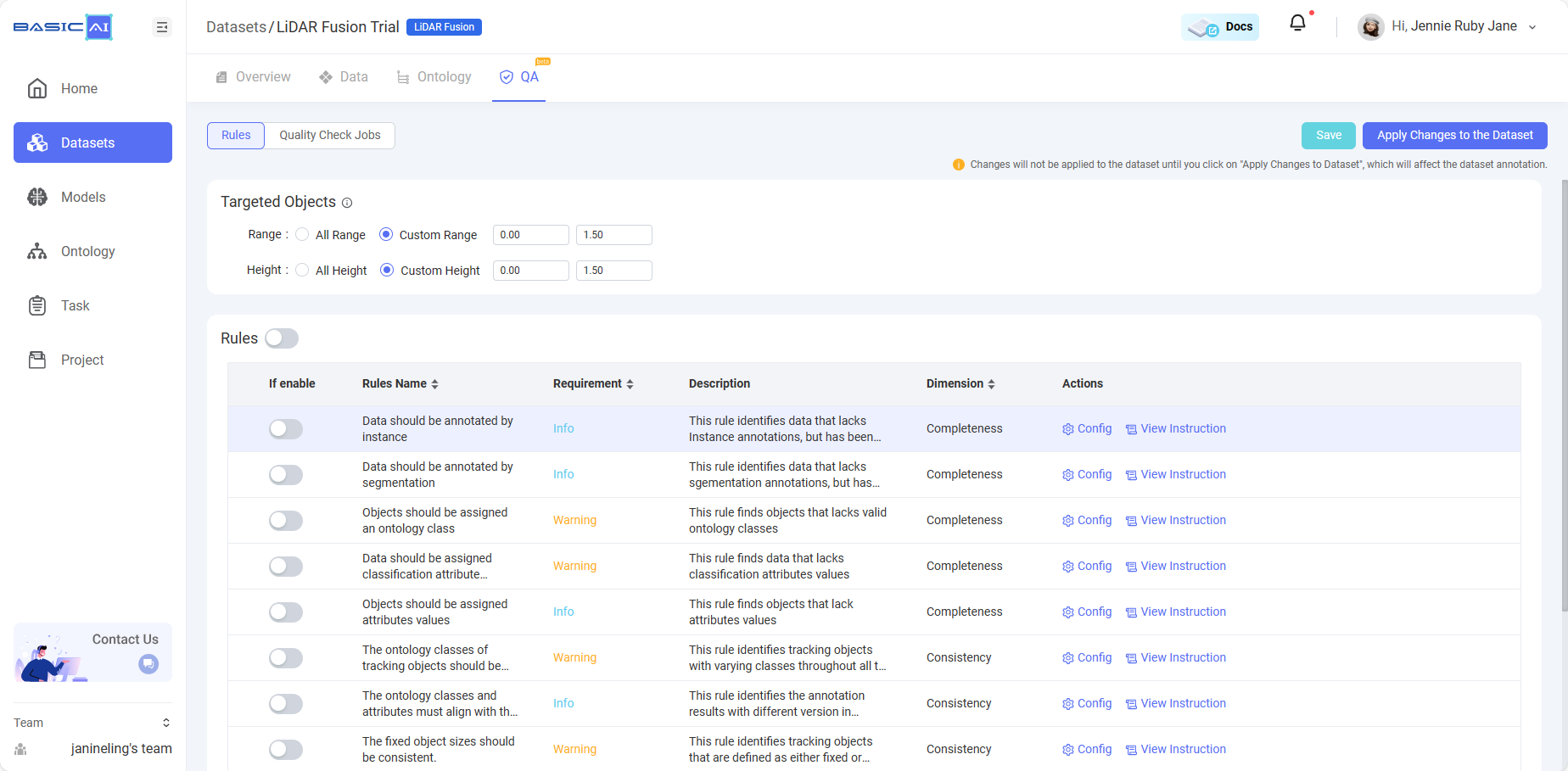
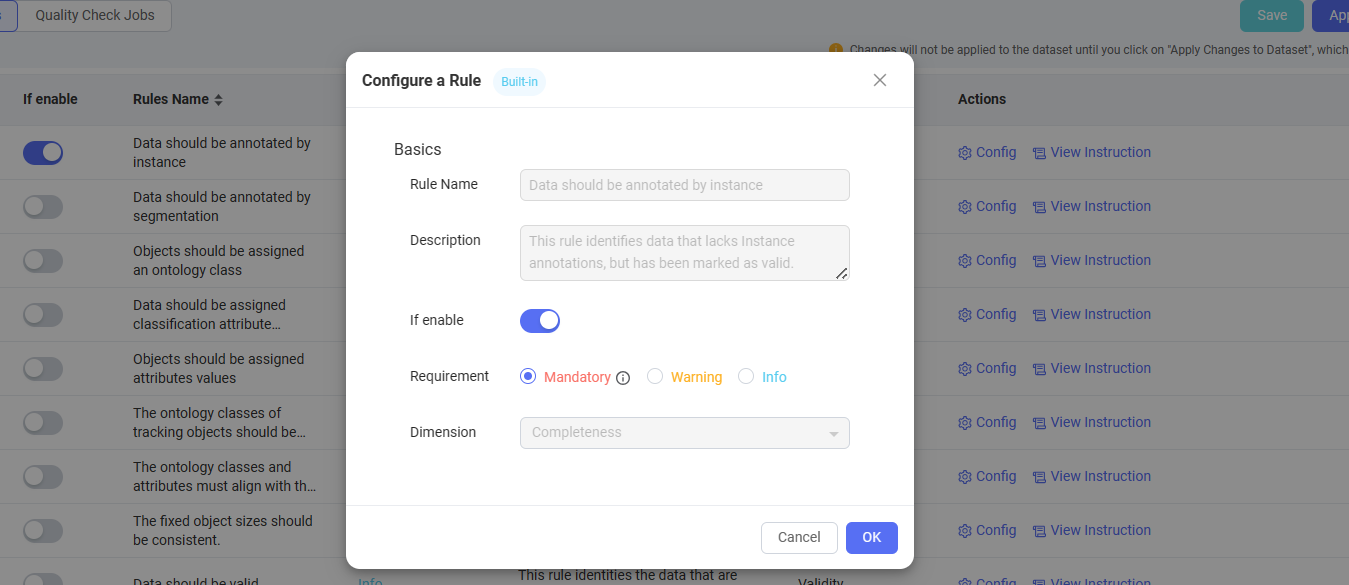
For LiDAR Fusion data, you can customize the range or height values according to your needs to detect whether the targeted objects are within or without the range or height limits.
The QA rules are designed according to different Data Type (LiDAR Fusion data or Image) and Annotation Type (Instance, Segmentation or both). They are further differentiated by the following levels: Data, Objects, Tracking Objects and Attributes. There are general QA rules, rules tailored to LiDAR Fusion data, and rules tailored to Image data. Please refer to the following table for the specifics and descriptions of our QA rules.
We also support to tailor QA rules according to your requirements. If you need to customize auto QA rules, please contact us on Slack or email us at [email protected].
| Data Type | Annotation Type | Rule Name | Level | Descriptions |
|---|---|---|---|---|
| Image & LiDAR Fusion | Instance | Data should be annotated by instance | Data | When there is no Instance result in the data, it will be regarded as violation of this rule. |
| Image & LiDAR Fusion | Segmentation | Data should be annotated by segmentation | Data | When there is no Segmentation result in the data, it will be regarded as violation of this rule. |
| Image & LiDAR Fusion | Instance & Segmentation | Objects should be assigned an ontology class | Object | To detect the objects which do not have valid ontology classes. |
| Image & LiDAR Fusion | Instance & Segmentation | Data should be assigned classification attribute values | Data | To detect data which do not have classification attribute values. |
| Image & LiDAR Fusion | Instance & Segmentation | Objects should be assigned attribute values | Attributes | To detect objects that lack attribute values. |
| Image & LiDAR Fusion | Instance & Segmentation | The ontology classes of tracking objects should be consistent across all the data | Attributes | To detect the tracking objects of which the tracking ID is the same, but the ontology class is different. |
| Image & LiDAR Fusion | Instance & Segmentation | The ontology classes and attributes must align with the most up-to-date ontology classes | Attributes | To identify the annotation results with different versions in terms of ontology classes and attributes. |
| Image & LiDAR Fusion | Instance & Segmentation | The ontology classifications and attributes must align with the most up-to-date ontology classifications | Attributes | To identify the annotation results with different versions in terms of ontology classifications and attributes. |
| Image & LiDAR Fusion | Instance & Segmentation | Data should be valid | Data | To identify data that are marked as invalid or unknown. |
| Image & LiDAR Fusion | Instance & Segmentation | Objects should conform to ontology constraints | Object | To detect objects that do not conform to ontology constraints. |
| LiDAR Fusion | Instance | The fixed object sizes should be consistent | Object | To identify tracking objects that are defined as either fixed or standard, but their sizes are inconsistent across all data. |
| LiDAR Fusion | Instance & Segmentation | Objects should be inside the range | Object | To detect objects that are outside the specified range. |
| Image | Instance | Classes inside a group should be unique | Tracking objects | To detect if there are duplicate classes within a group. |
Real-time Auto QA
When annotating data on the Tool page, you can click the yellow QA button on the right corner of the top workflow bar and then click Run. This will enable auto QA on the current data. For example, if the data are LiDAR Fusion, the range or height limits have been customized before on the QA Rules page, and the selected QA rule is "Objects should be inside the range", after running auto QA, the system will find the possible objects which fall outside the range:
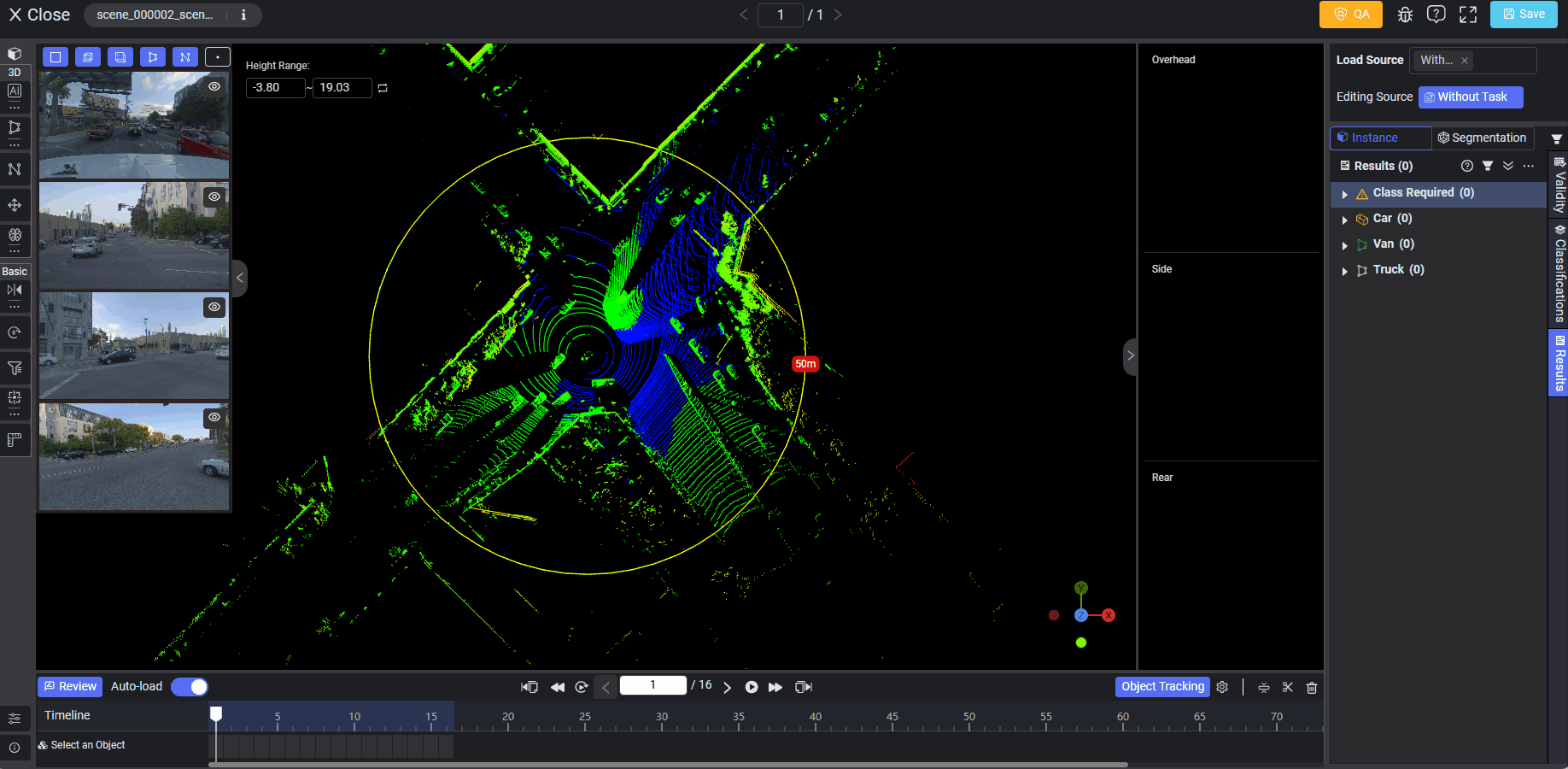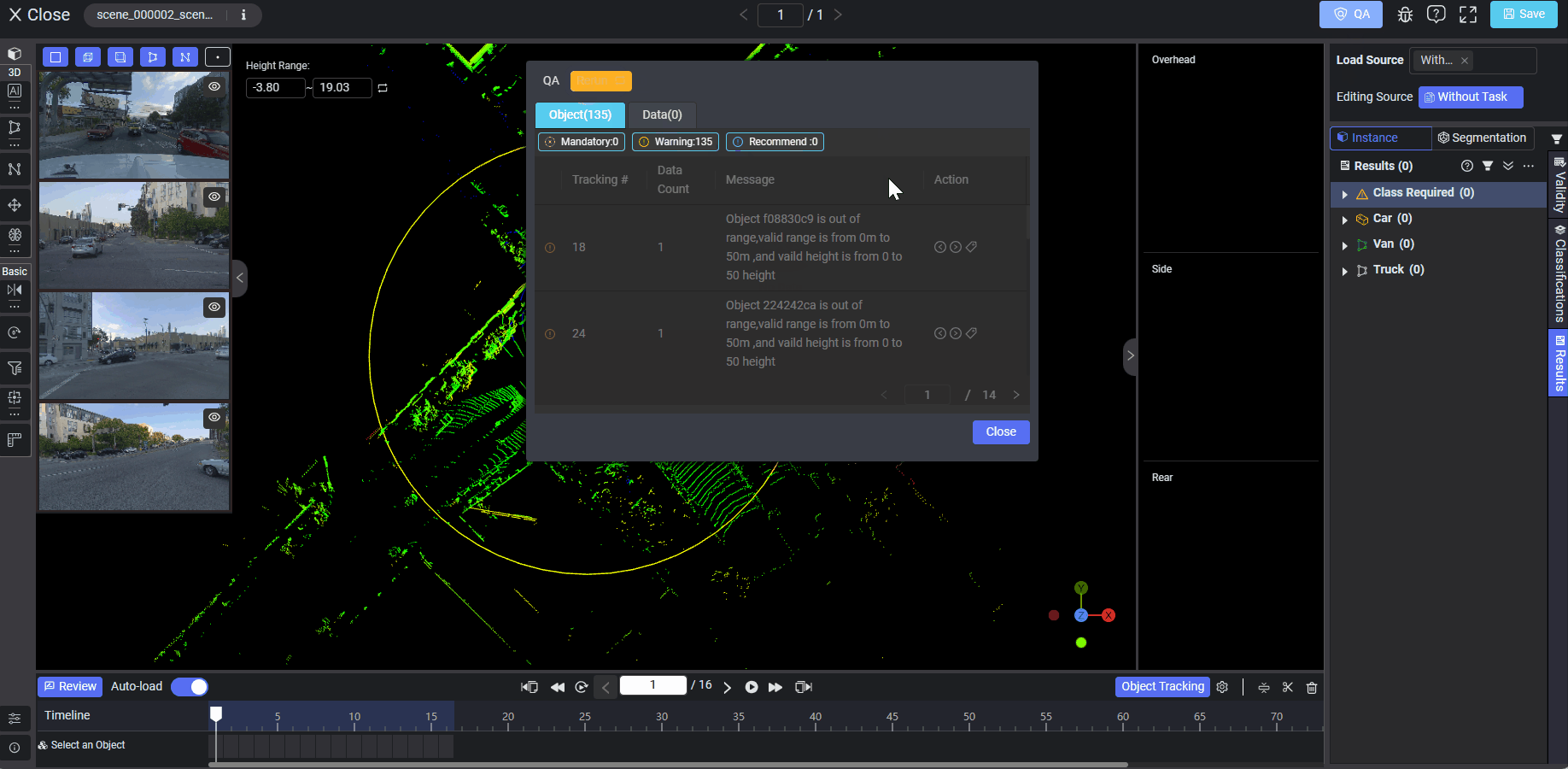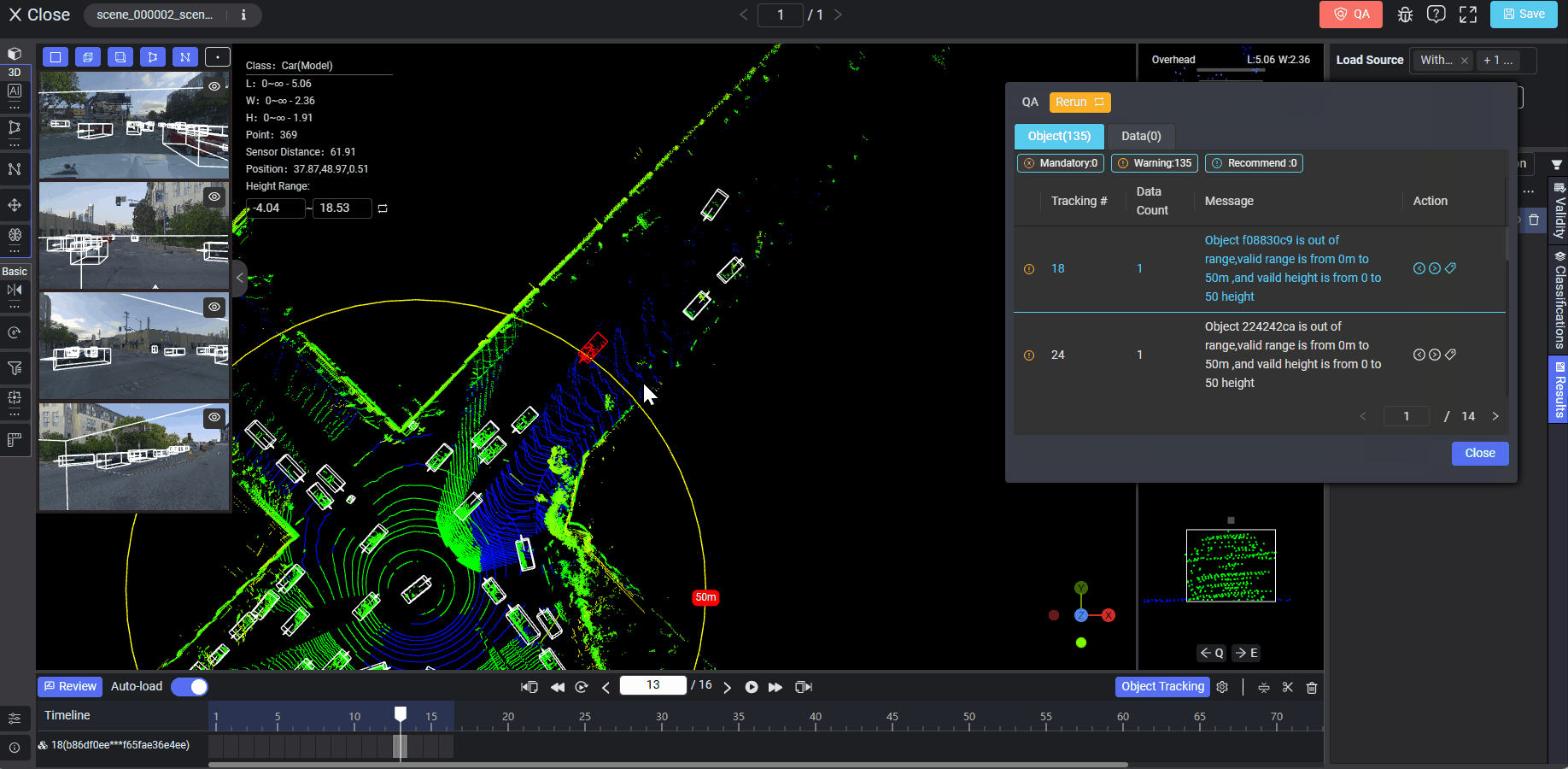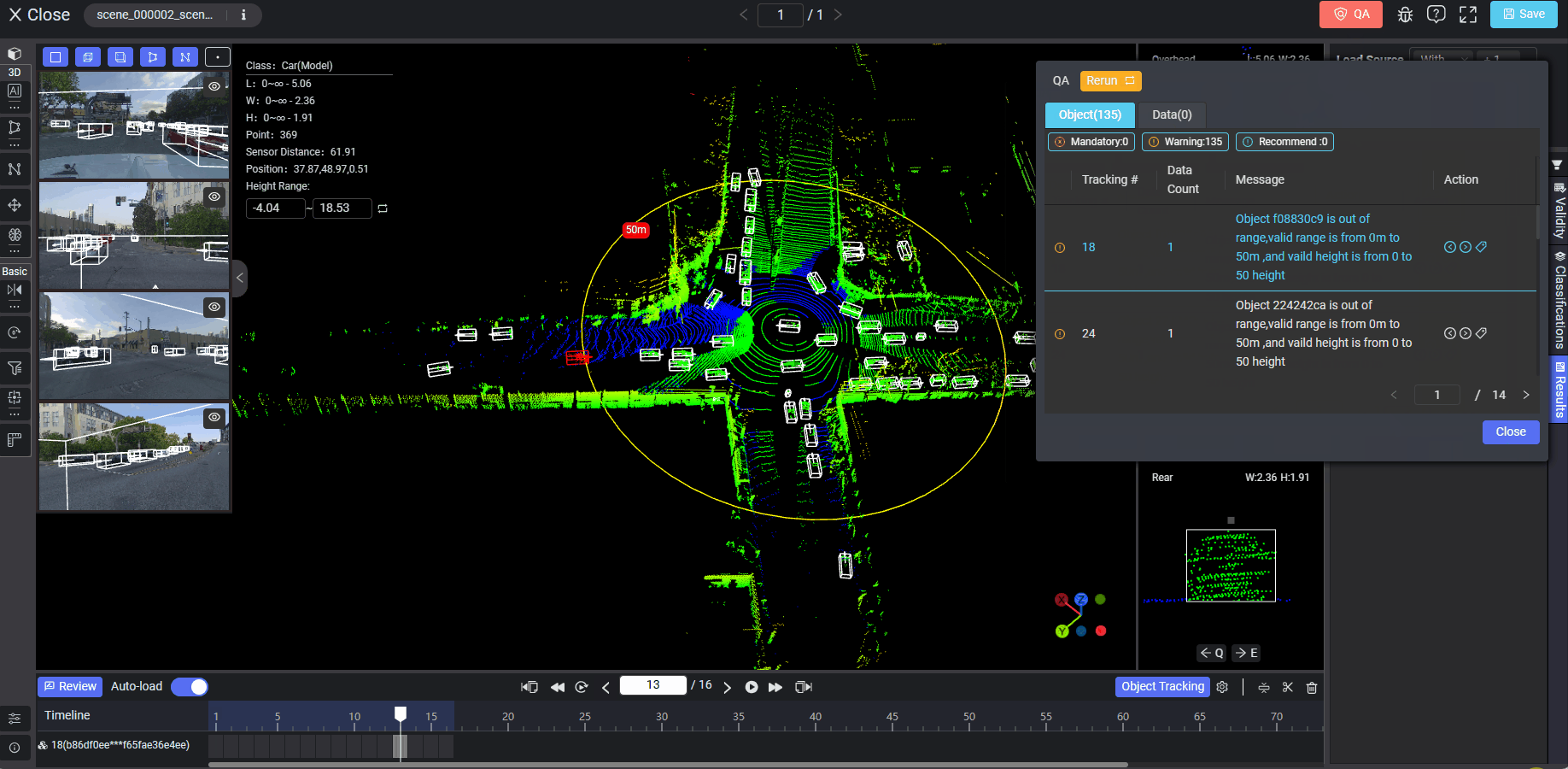
If a rule is set as mandatory, it will force annotators to run all QA rules, and if a mandatory rule is violated, it will prevent annotators from submitting data.
After running auto QA on the tool page, any violations will show on the pop-up panel with detailed information such as the QA rule level (Object or Data), requirement type (mandatory, warning, or recommend), and the violation record list. Clicking on each record, and the data or object in violation will be highlighted in red automatically on the right panel in the section of Validity, Classifications or Results. The auto QA result display will vary according to different data types, annotation types, or rule levels (Data, Objects, Tracking Objects, or Attributes).
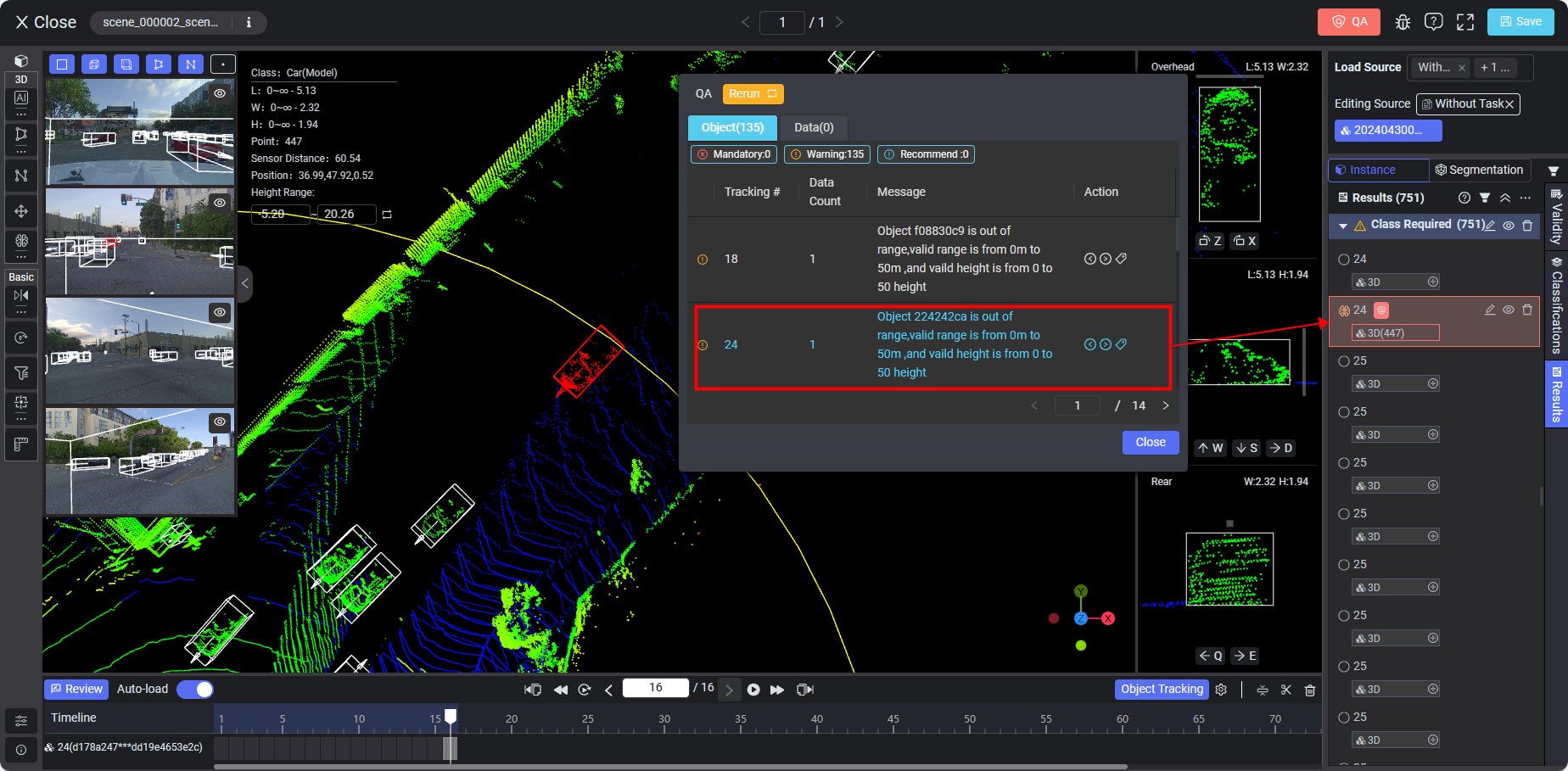
Bulk Auto QA
For performing bulk auto QA on all the data in a dataset, you can click the Quality Check Jobs tab on the Dataset-QA page, build data indexes and then create a quality check job.
- Click
Buildto build data indexes first. - Click
Create a Quality Check Job-> enter Quality Check Name -> Choose to customize Score Weight or keep it as Average -> Select up to 5 results -> Click and select rules -> ClickConfirm. Then the QC job is created and running. Wait for a few seconds and you can clickView ReportorView Violations.
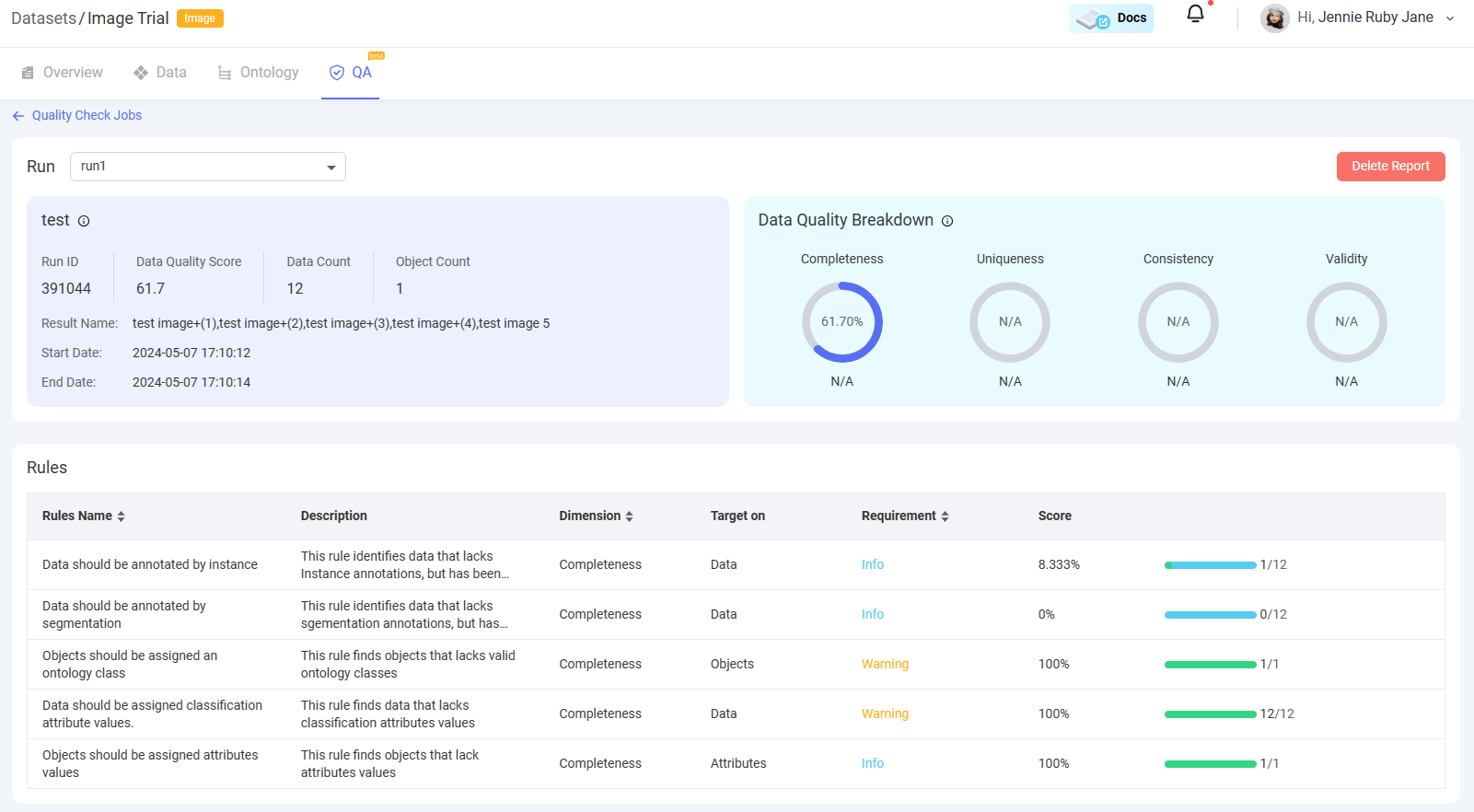
The QC report will be like the image below, which provides basic info of the QC job, data quality breakdown from the four dimensions: completeness, uniqueness, consistency, and validity, and also the selected rule list with running scores.
Updated about 1 year ago