📙Common use cases of how to use OpenAPI in BasicAI
🔑 Prerequisite
API Key
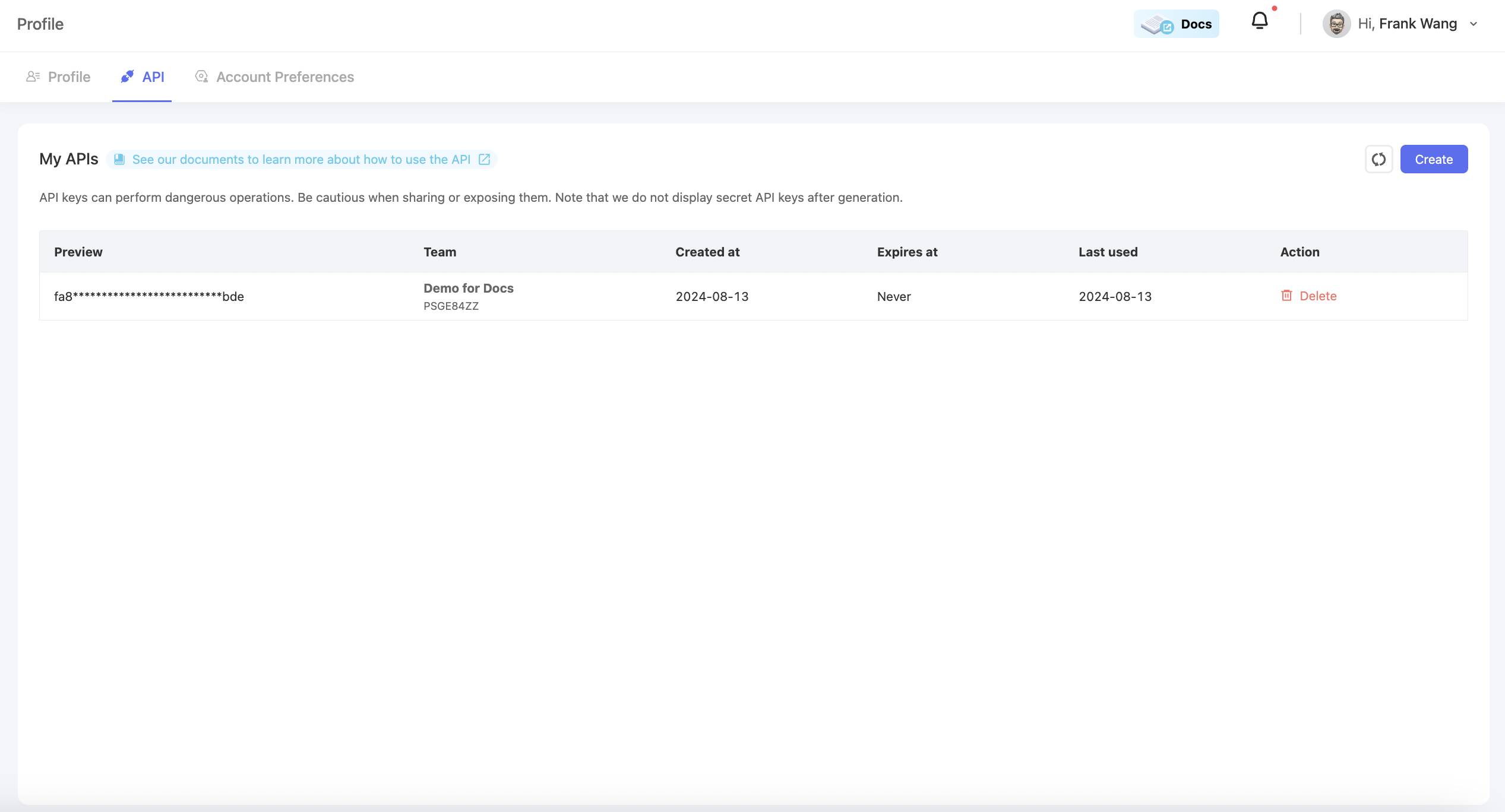
Before starting anything with OpenAPI, generate an API Key under your profile. You Can find an API key tab under your profile. Select a team and create an API key.
Please copy and save your API key before closing the dialog!
📙Usecases
Case1: Start uploading LiDAR scenes from scratch
Google Colab Version
Here is the OpenAPI example in Google Colab. You can directly download it or learn the example step by step below
Step1: Set up
from pathlib import Path
import requests
MY_API_KEY = "yourAPI key"
headers = {
"Authorization": f"ApiKey {MY_API_KEY}"
}Step 2:Create a Dataset
Data and Scenes must be inside a dataset. You can use the following code to create a dataset.
url = "https://open.basic.ai/api/v1/dataset/create"
payload = {"name": "lidar_dataset", "type": "LIDAR"}
dataset_resp = requests.post(
url,
json=payload,
headers=headers
)
print(dataset_resp.text)Step 3:Uploda Data to S3
Basic requires files to first upload to S3 to ensure uploading stability. So you need to obtain pre-signed URLs to upload your data finally.
origin_path = Path(r"your_data")
pcds = list(origin_path.rglob("*.pcd"))
# batch generate pre signed upload url
url = "https://open.basic.ai/api/v1/storage/batchGeneratePreSignedUploadUrl"
payload = [
{
"deviceName": "lidar_point_cloud_0",
"filename": x.name,
"size": x.stat().st_size
}
for x in pcds
]
presigned_resp = requests.post(
url,
json=payload,
headers=headers
)
print(json.dumps(presigned_resp.json()))You are expected to see the following response.
{
"code": "OK",
"message": "Ok",
"data": [
{
"preSignedUrl": "https://basicai-prod-app-default.s3.us-west-2.amazonaws.com/upload/team_90104/20240918/8ba84205-8a00-4621-bc2c-9cfc0454421b/000.pcd?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20240918T020127Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3600&X-Amz-Credential=AKIAUXHLIG3Q6QTJJGJW/20240918/us-west-2/s3/aws4_request&X-Amz-Signature=78b9b5c63e19a66d42e5d66e9b9528bf7f6d9332305ee946e94d842ea4de1bf2",
"tempFileId": "b7973e45-a9d3-4923-b32c-6d646a4a5aaa"
},
{
"preSignedUrl": "https://basicai-prod-app-default.s3.us-west-2.amazonaws.com/upload/team_90104/20240918/cb9c4549-58d3-47eb-bcc6-434a8779b8e0/001.pcd?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20240918T020127Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3600&X-Amz-Credential=AKIAUXHLIG3Q6QTJJGJW/20240918/us-west-2/s3/aws4_request&X-Amz-Signature=6a2bebb626142bc06fe040001633e0429b02b619e3e7db3fe0edf6ed02aa8adc",
"tempFileId": "832ca040-e659-4f6c-9664-c87fbbb3ed74"
},
{
"preSignedUrl": "https://basicai-prod-app-default.s3.us-west-2.amazonaws.com/upload/team_90104/20240918/69220cab-5ae9-4d8a-8313-5ea66c835a9f/002.pcd?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20240918T020127Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3599&X-Amz-Credential=AKIAUXHLIG3Q6QTJJGJW/20240918/us-west-2/s3/aws4_request&X-Amz-Signature=a842afab1394b72a93f90a9b5020066c7c9a68268258497c231cb12bf86cb466",
"tempFileId": "c7b5d010-78c8-4367-9480-5114c990e249"
},
{
"preSignedUrl": "https://basicai-prod-app-default.s3.us-west-2.amazonaws.com/upload/team_90104/20240918/e4477d06-efad-411f-8bac-e97659677726/003.pcd?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20240918T020127Z&X-Amz-SignedHeaders=host&X-Amz-Expires=3599&X-Amz-Credential=AKIAUXHLIG3Q6QTJJGJW/20240918/us-west-2/s3/aws4_request&X-Amz-Signature=77606732bbed5564b12b33d7d65c66754ae8bb1e8b540fb464e2d9bf5d69188f",
"tempFileId": "660aa018-0e71-431b-ae4f-580f4fa9c9ec"
}
]
}Finally, upload files through the pre-signed URLs
for url_dict, file in zip(presigned_resp.json()["data"], pcds):
files = {
"file": (file.name, open(file, "rb"), "application/octet-stream")
}
response = requests.put(url_dict["preSignedUrl"], files=files)
print(response)Step 4: Add Scene to Dataset
After uploading files through the pre-signed URLs, you must add them to the dataset as data or a scene. Here, take the scene as an example; if you want to upload as data directly, please refer add data to dataset
NoteIf you are uploading multimodal data like lidar fusion, the tempfileIds will be a list
from itertools import islice
def batched(data_list, batch_size):
it = iter(data_list)
while batch := list(islice(it, batch_size)):
yield batchn_data_per_frame = 2
for i, batch in enumerate(batched(zip(presigned_resp.json()["data"], pcds), n_data_per_frame)):
url = f"https://open.basic.ai/api/v1/dataset/addScene/{dataset_resp.json()['data']['id']}"
payload = {
"name": f"scene_{i}", # scene name
"datas": [
{
"name": file.stem, # data name, not file name
"tempFileIds": [url_dict["tempFileId"]] # if your data contains multimodal data, there will be multiple elements in the list
}
for url_dict, file in batch
]
}
scene_resp = requests.post(
url,
json=payload,
headers=headers
)
print(scene_resp.text)After you received the 200 response, you successfully uploaded your files as a scene in BasicAI!